In this post, I will talk about the probabilistic derivation of the Kalman filter, which is a nice introduction to a paper I intent to write in the near future, A Disentangled Recognition and Nonlinear Dynamics Model for Unsupervised Learning by M. Fraccaro et al. 1
In short, the Kalman filtering deals with the task of finding the filtered posterior of a Linear Gaussian State Space Model, that is p(zt∣y1:t,u1:t). There is also the Kalman smoother (or Rauch–Tung–Striebel smoother), which gives the smoothed posterior p(zt∣y1:T,u1:T), note that the difference is that the smoother uses the entire sequence while the filter only uses data available up to the current time.
Many of the derivations in this post have been extracted from Probabilistic Machine Learning: Advanced Topics by Kevin Patrick Murphy 2, which is a reference I cannot recommend enough to anyone interested in the topic.
Linear Gaussian State Space Model
State-space models (SSM) make use of the state variables to describe the system with a set of first-order differential (or differences) equations.
ztyt=f(zt−1,ut,qt)=h(zt,ut,y1:t−1,rt)
The SSM consist of:
Hidden stateszt∈RNz describe the system’s true internal condition, that evolves over time according to the dynamics or transition model.
Inputsut∈RNu are the external signals that influence the evolution of the hidden state.
Observationsyt∈RNy are the measured quantities of the system.
Process noiseqt is the uncertainty of how the hidden state evolves over time. This can be due to random disturbances and modeling simplifications among others.
Observation noisert is the uncertainty in the sensor measurements.
For instance: for a rocket, the hidden state could be the position and velocity, the input would be the amount of thrust delivered by the engines and the observation could consist of the altitude measurements. The process noise could come from unexpected winds, or differences in the expected atmospheric density. The observation noise could be random biases of the sensor, drifts, etc.
The SSM is normally written as a probabilistic model given by the dynamics model or transition modelp(zt∣zt−1,ut) and observation model or measurement modelp(yt∣zt,ut,y1:t−1).
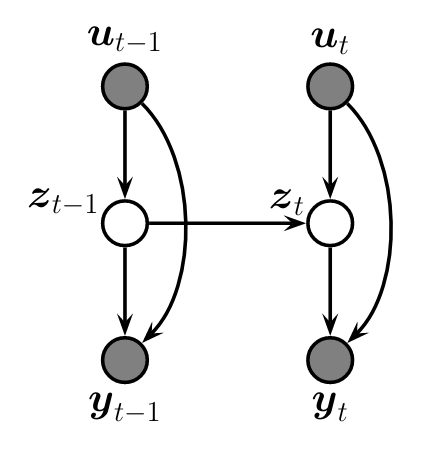
The figure below shows the graphical model of the state-space model
Architecture of the memory cell. Source: Murphy, K. P.
If f and h are linear functions then we have a linear-Gaussian SSM (LGSSM), this is normally written as
ztyt=Atzt−1+Btut+wt=Ctzt+Dtut+δt
where At is the state transition matrix, Bt the control-input matrix, Ct the observation matrix, and Dt the feed-through matrix, which maps the input ut directly to the observation and is often 0 as normally inputs affect the observations only through the state.
Also, normally we assume that the process and observation noises are multivariable Gaussian-distributed random variables with mean 0 and some covariance.
ϵtδt∼N(0,Qt)∼N(0,Rt)
There are two strong reasons for modelling this noises as Gaussian.
They are stable by conditioning. Which means that if we have a Gaussian likelihood and prior the posterior will also be Gaussian.
Since any linear transformation of a multivariate normal distribution is also multivariate normally distributed we can rewrite the transitions and observation model as
Note that we assume the standard Markov observation model in which yt⊥y1:t−1∣(zt,ut), that is the current observation is independent of the previous observations given the current latent state and control.
Likelihood, Posterior and Prior Beliefs
The goal of the Kalman filter is then to compute the posterior distribution of the hidden state given all measurements and controls so far:
p(zt∣y1:t,u1:t)=p(zt∣y1:t,u1:t)
by direct application of the Bayes rule (Posterior = Likelihood × Prior / Evidence)
note that u1:t are known so they are always given and not random variables. We can then use the chain rule in the numerator, and use the property that in the SSM the current observation only depends on the current state and current input
The denominator can be expressed as the marginalized joint distribution, then substitute the expression above and take outside of the integral the terms that do not depend on zt
In the Bayesian paradigm, the concepts of posterior, likelihood and prior are extremely important.
First, the likelihood relates the data with a set of parameters. In the Kalman filter this relates the observations yt with the current state zt and control ut. This likelihood is directly obtained from the observation model defined above.
It reads as the probability of getting a measurement yt for a given state zt and control ut.
The prior is our belief of the state before seeing a measurement.
p(zt∣y1:t−1,u1:t)
Since both the likelihood and the prior are multivariate Gaussians the result will be a Gaussian as well, since the evidence is a constant that scales the resulting distribution, in practice it is dropped, as we only care about the mean and covariance of the posterior to compute the Kalman filter.
The Kalman Filter
The Kalman Filter is the algorithm to obtain the exact Bayesian filtering for Linear Gaussian State Space Models, it finds p(zt∣y1:t)=N(zt∣μt∣t,Σt∣t) where μt∣t,Σt∣t refer to the posterior mean and covariance given the observations y1:t and the control u1:t. Note that there is an analytically close form because all the distributions are Gaussian.
The algorithm consist in a predictor, which get the one-step prediction using the transition model,
Predictor step
The predictor step involves the computation of the prior.
First of all note that if zt−1 were known, the distribution of zt would simply be
p(zt∣y1:t−1,u1:t)=p(zt∣zt−1,ut)
however, zt−1 is the hidden state so we only know its distribution
zt−1∼N(μt−1∣t−1,Σt−1∣t−1)
using the total law of probability and the fact that zt is independent of y1:t−1 given zt−1 we integrate over the uncertainty in zt−1
Finally note that to marginalize in a joint distribution one simply drops the irrelevant variables (the ones to marginalize) from the mean vector and covariance matrix, in our case we marginalizing with respect to zt−1 we remain with
In order to solve this we will build the joint distribution p(zt,yt∣y1:t−1,u1:t) and then take the conditional distribution inside the joint Gaussian p(zt∣yt,y1:t−1,u1:t). First, we define the joint Gaussian
so that we have the mean and covariance of the posterior
p(zt∣y1:t,u1:t)=N(zt∣μt∣t,Σt∣t)
Footnotes
Fraccaro, M., Kamronn, S., Paquet, U., & Winther, O. (2017). A disentangled recognition and nonlinear dynamics model for unsupervised learning. Advances in neural information processing systems, 30. ↩
Murphy, K. P. (2023). Probabilistic machine learning: Advanced topics. MIT press. ↩
Masnadi-Shirazi, H., Masnadi-Shirazi, A., & Dastgheib, M. A. (2019). A step by step mathematical derivation and tutorial on kalman filters. arXiv preprint arXiv:1910.03558. ↩
Comments
No comments yet.